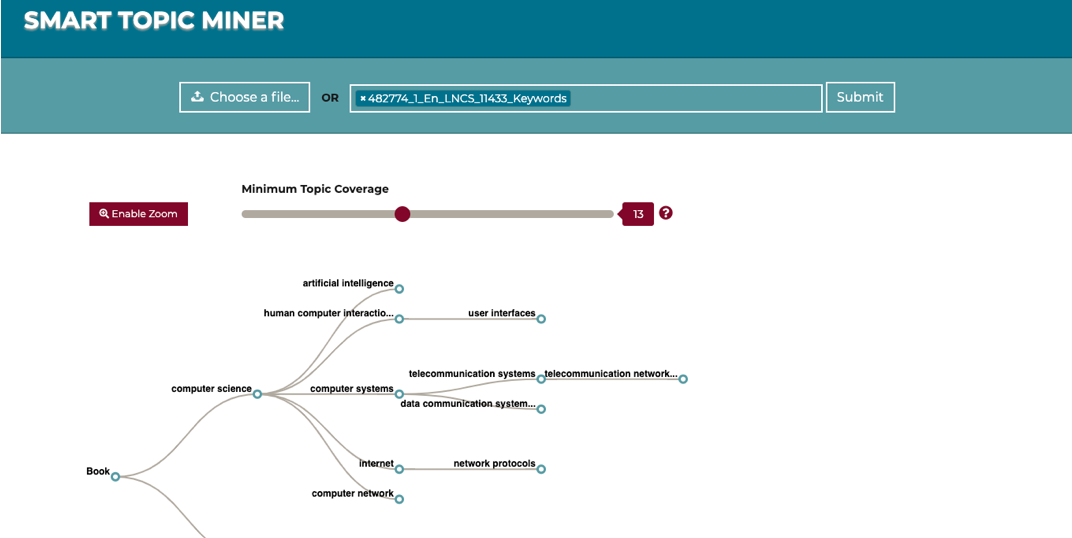
Producing a robust and comprehensive representation of the research topics covered by a scientific publication is a crucial task that has a major impact on its retrievability and consequently on the diffusion of the relevant scientific ideas. Springer Nature, the world’s largest academic book publisher, has typically entrusted this task to the most expert editors, which had to manually analyse new books and produce a list of the most relevant topics. To support Springer Nature in this task, we developed Smart Topic Miner, an application that assists the editorial team in annotating proceedings books according to a large-scale ontology of research areas. Over the past three years, we evolved this application according to the editors’ feedback and developed a new engine, a new interface, and several other functionalities. In this demo paper, we present Smart Topic Miner 2, the most recent version of the tool, which is being regularly utilized by editors in Germany, China, Brazil, and Japan to annotate all book series covering conference proceedings in Computer Science, for a total of about 800 volumes per year.
Tag: Topic Classification
Improving Editorial Workflow and Metadata Quality at Springer Nature
Identifying the research topics that best describe the scope of a scientific publication is a crucial task for editors, in particular because the quality of these annotations determine how effectively users are able to discover the right content in online libraries. For this reason, Springer Nature, the world’s largest academic book publisher, has traditionally entrusted this task to their most expert editors. These editors manually analyse all new books, possibly including hundreds of chapters, and produce a list of the most relevant topics. Hence, this process has traditionally been very expensive, time-consuming, and confined to a few senior editors. For these reasons, back in 2016 we developed Smart Topic Miner (STM), an ontology-driven application that assists the Springer Nature editorial team in annotating the volumes of all books covering conference proceedings in Computer Science. Since then STM has been regularly used by editors in Germany, China, Brazil, India, and Japan, for a total of about 800 volumes per year. Over the past three years the initial prototype has iteratively evolved in response to feedback from the users and evolving requirements.