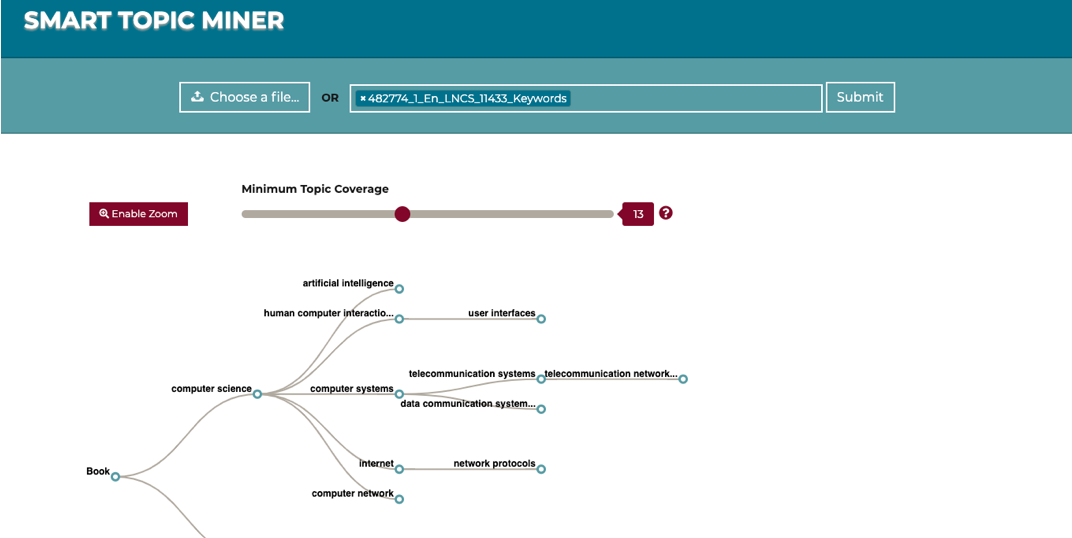
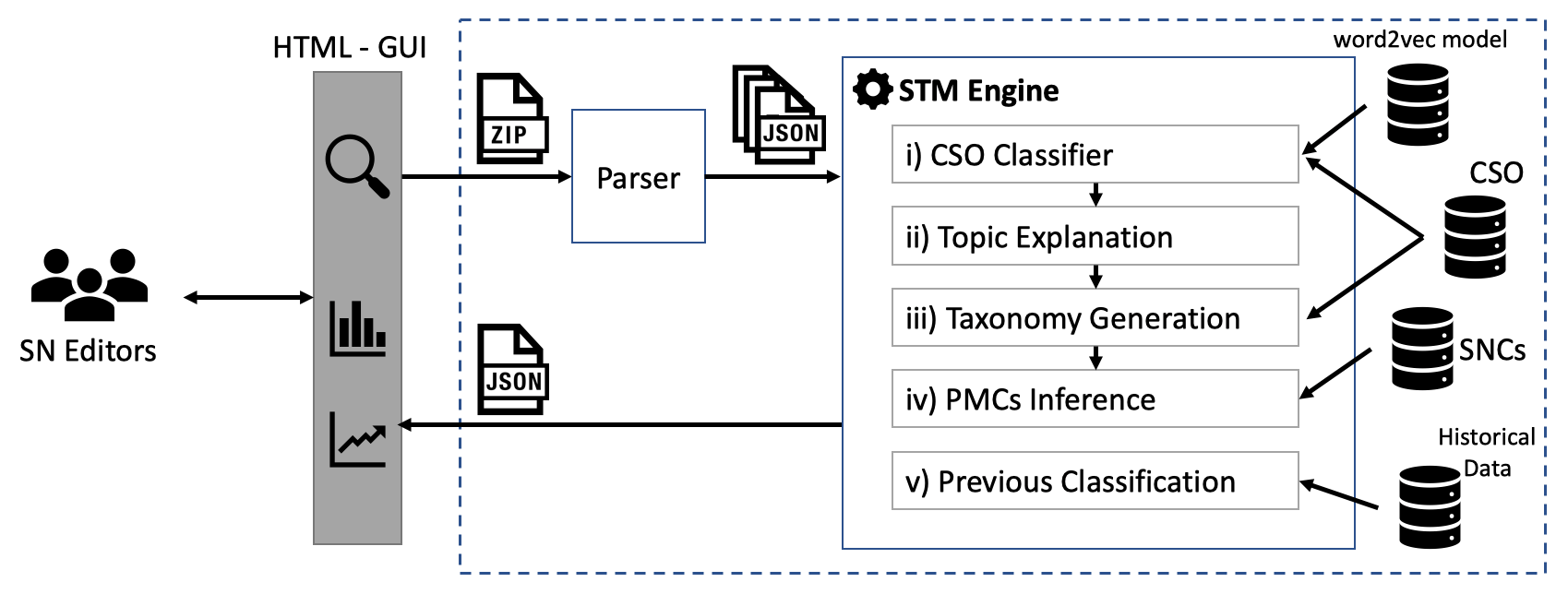
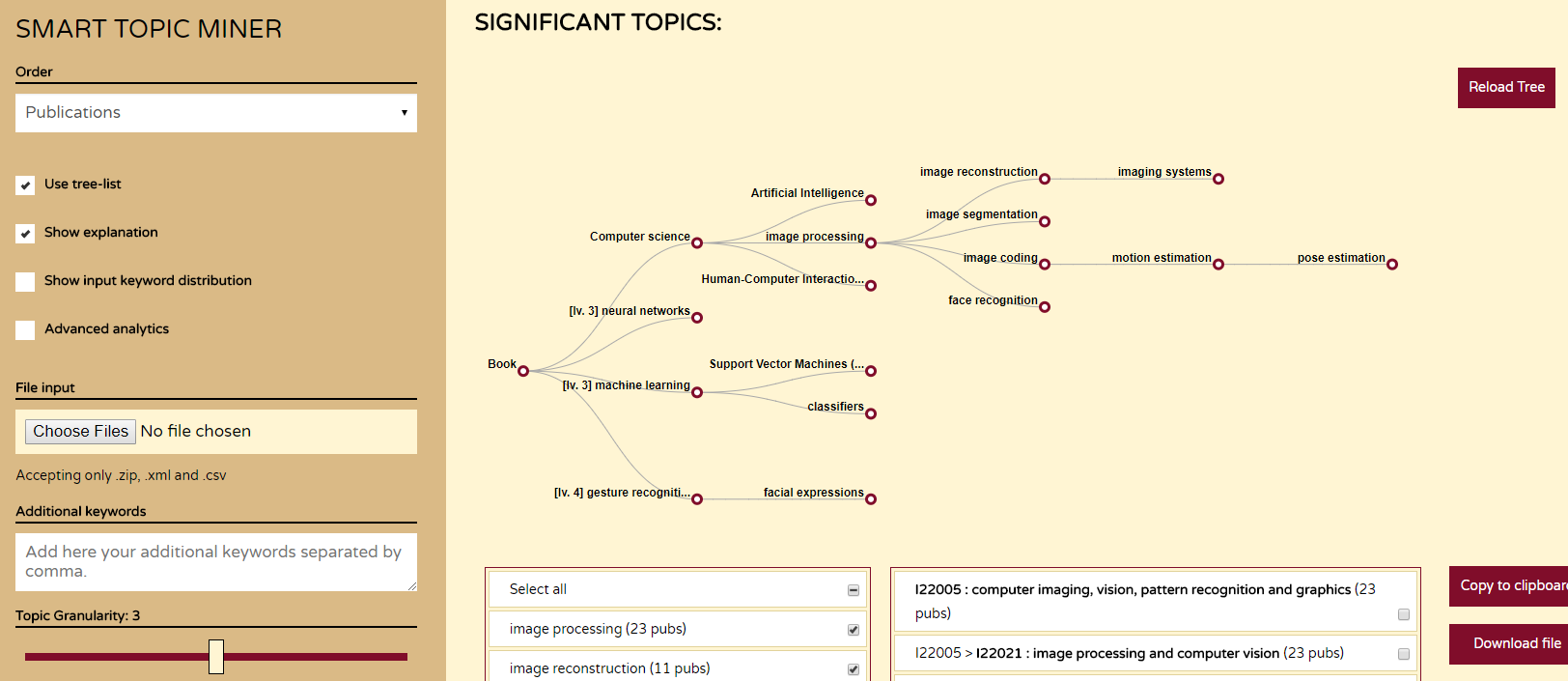
Producing a robust and comprehensive representation of the research topics covered by a scientific publication is a crucial task that has a major impact on its retrievability and consequently on the diffusion of the relevant scientific ideas. Springer Nature, the world’s largest academic book publisher, has typically entrusted this task to the most expert editors, which had to manually analyse new books and produce a list of the most relevant topics. To support Springer Nature in this task, we developed Smart Topic Miner, an application that assists the editorial team in annotating proceedings books according to a large-scale ontology of research areas. Over the past three years, we evolved this application according to the editors’ feedback and developed a new engine, a new interface, and several other functionalities. In this demo paper, we present Smart Topic Miner 2, the most recent version of the tool, which is being regularly utilized by editors in Germany, China, Brazil, and Japan to annotate all book series covering conference proceedings in Computer Science, for a total of about 800 volumes per year.
Tag: Scholarly Ontologies
Improving Editorial Workflow and Metadata Quality at Springer Nature
Identifying the research topics that best describe the scope of a scientific publication is a crucial task for editors, in particular because the quality of these annotations determine how effectively users are able to discover the right content in online libraries. For this reason, Springer Nature, the world’s largest academic book publisher, has traditionally entrusted this task to their most expert editors. These editors manually analyse all new books, possibly including hundreds of chapters, and produce a list of the most relevant topics. Hence, this process has traditionally been very expensive, time-consuming, and confined to a few senior editors. For these reasons, back in 2016 we developed Smart Topic Miner (STM), an ontology-driven application that assists the Springer Nature editorial team in annotating the volumes of all books covering conference proceedings in Computer Science. Since then STM has been regularly used by editors in Germany, China, Brazil, India, and Japan, for a total of about 800 volumes per year. Over the past three years the initial prototype has iteratively evolved in response to feedback from the users and evolving requirements.
New release: CSO Classifier v2.1
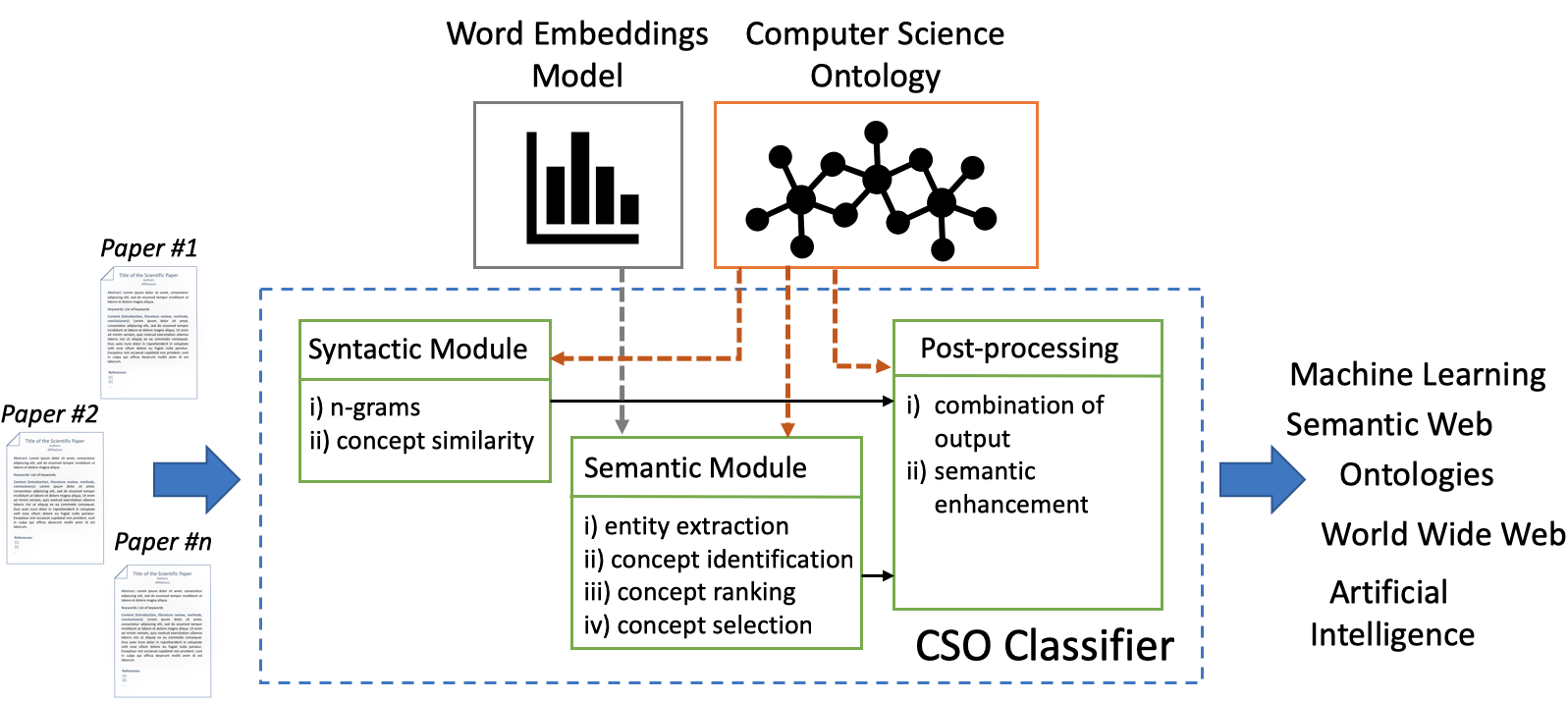
We are pleased to announce that we recently created a new release of the CSO Classifier (v2.1), an application for automatically classifying research papers according to the Computer Science Ontology (CSO). Recently, we have been intensively working on improving its scalability, removing all its bottlenecks and making sure it could be run on large corpus. […]

CSO Classifier
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this page, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science.
Computer Science Ontology
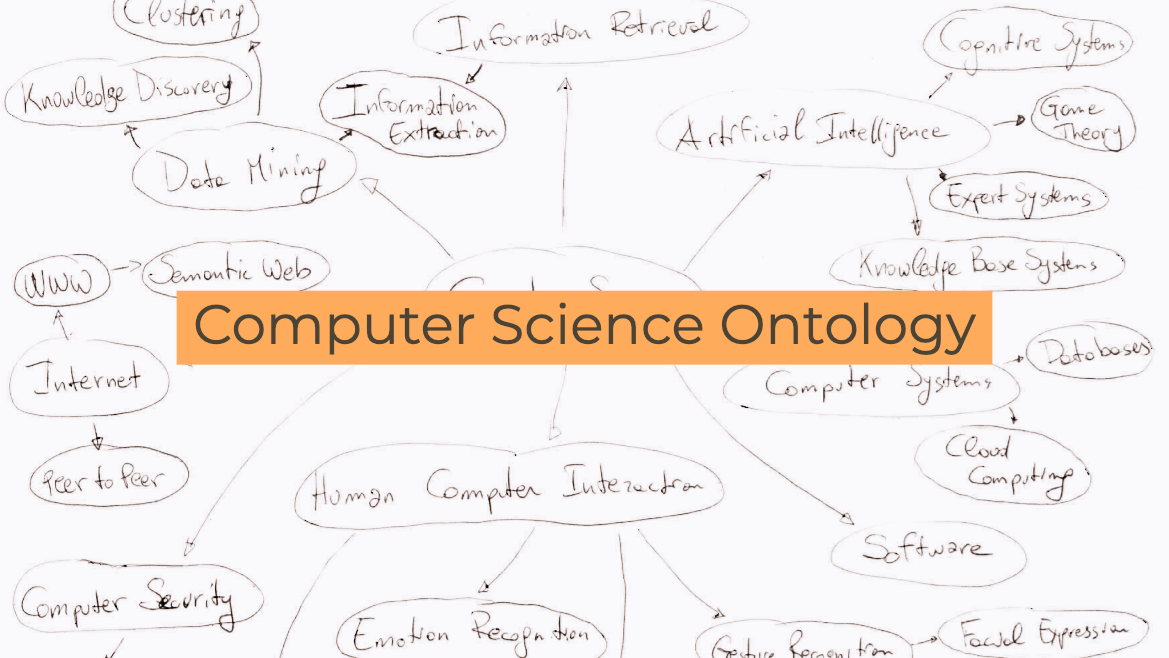
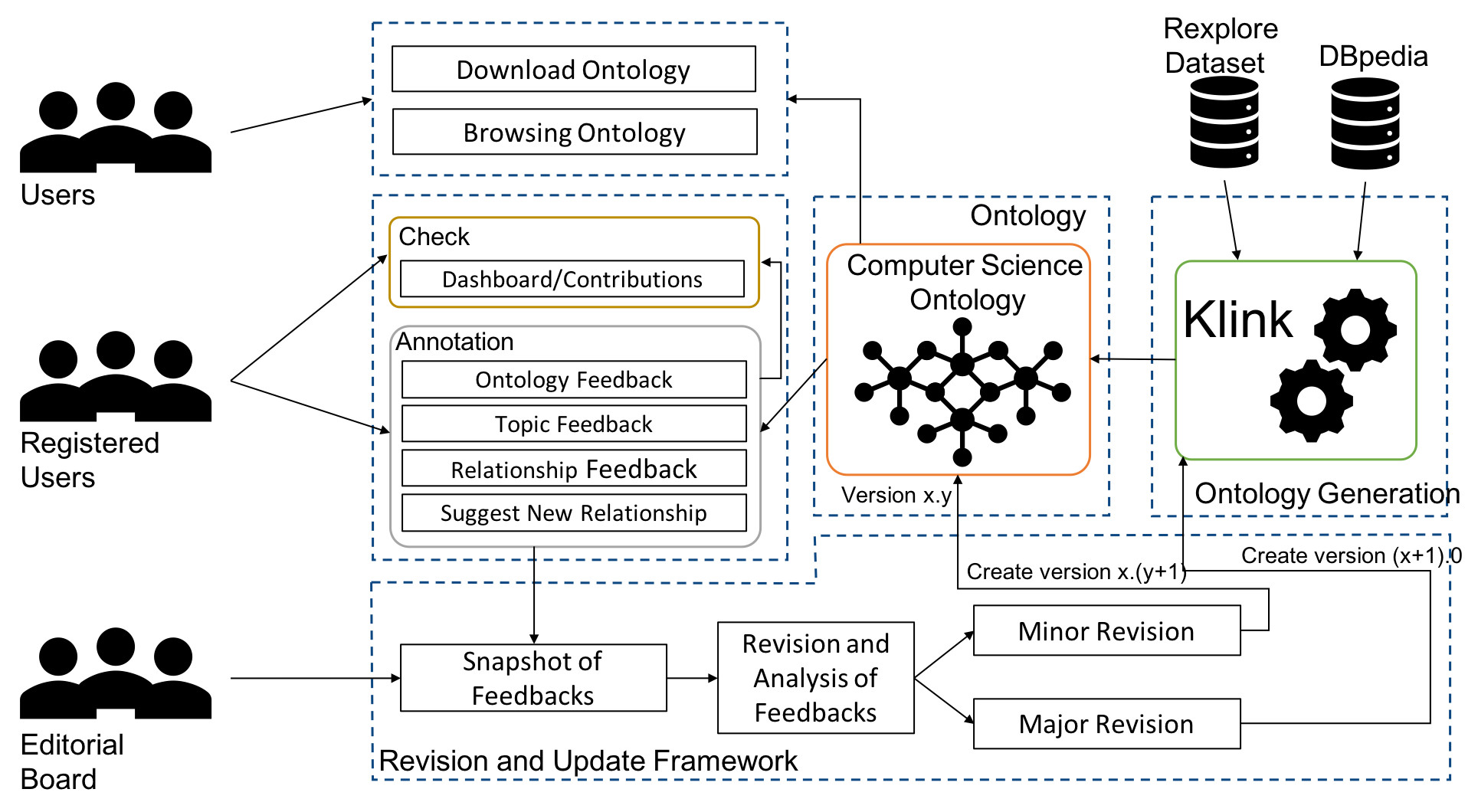
The Computer Science Ontology is a large-scale ontology of research areas that was automatically generated using the Klink-2 algorithm on a dataset of about 16 million publications, mainly in the field of Computer Science. In the rest of the paper, we will refer to this corpus as the Rexplore dataset.
The current version of CSO includes 14,164 topics and 162,121 semantic relationships. The main root is Computer Science; however, the ontology includes also a few secondary roots, such as Linguistics, Geometry, Semantics, and so on.
CSO presents two main advantages over manually crafted categorisations used in Computer Science (e.g., 2012 ACM Classification, Microsoft Academic Search Classification). First, it can characterise higher-level research areas by means of hundreds of sub-topics and related terms, which enables to map very specific terms to higher-level research areas. Secondly, it can be easily updated by running Klink-2 on a set of new publications.

Classifying Research Papers with the Computer Science Ontology
The CSO Classifier is an application for automatically classifying academic papers according to the rich taxonomy of topics from CSO. The aim is to facilitate the adoption of CSO across the various communities engaged with scholarly data and to foster the development of new applications based on this knowledge base.
The Computer Science Ontology: A Large-Scale Taxonomy of Research Areas
Ontologies of research areas are important tools for characterising, exploring, and analysing the research landscape. Some fields of research are comprehensively described by large-scale taxonomies, e.g., MeSH in Biology and PhySH in Physics. Conversely, current Computer Science taxonomies are coarse-grained and tend to evolve slowly. For instance, the ACM classification scheme contains only about 2K research topics and the last version dates back to 2012. In this paper, we introduce the Computer Science Ontology (CSO), a large-scale, automatically generated ontology of research areas, which includes about 26K topics and 226K semantic relationships. It was created by applying the Klink-2 algorithm on a very large dataset of 16M scientific articles.
Springer Nature video
Couple of months ago, with my team, we attended the Springer Nature HackDay (here is the post). Just not long ago, Springer Nature released a short video featuring us. Summarised is also my interview, in which I discuss the advantages of making scholarly datasets, as SciGraph, available to anyone. Other media Building on the success […]
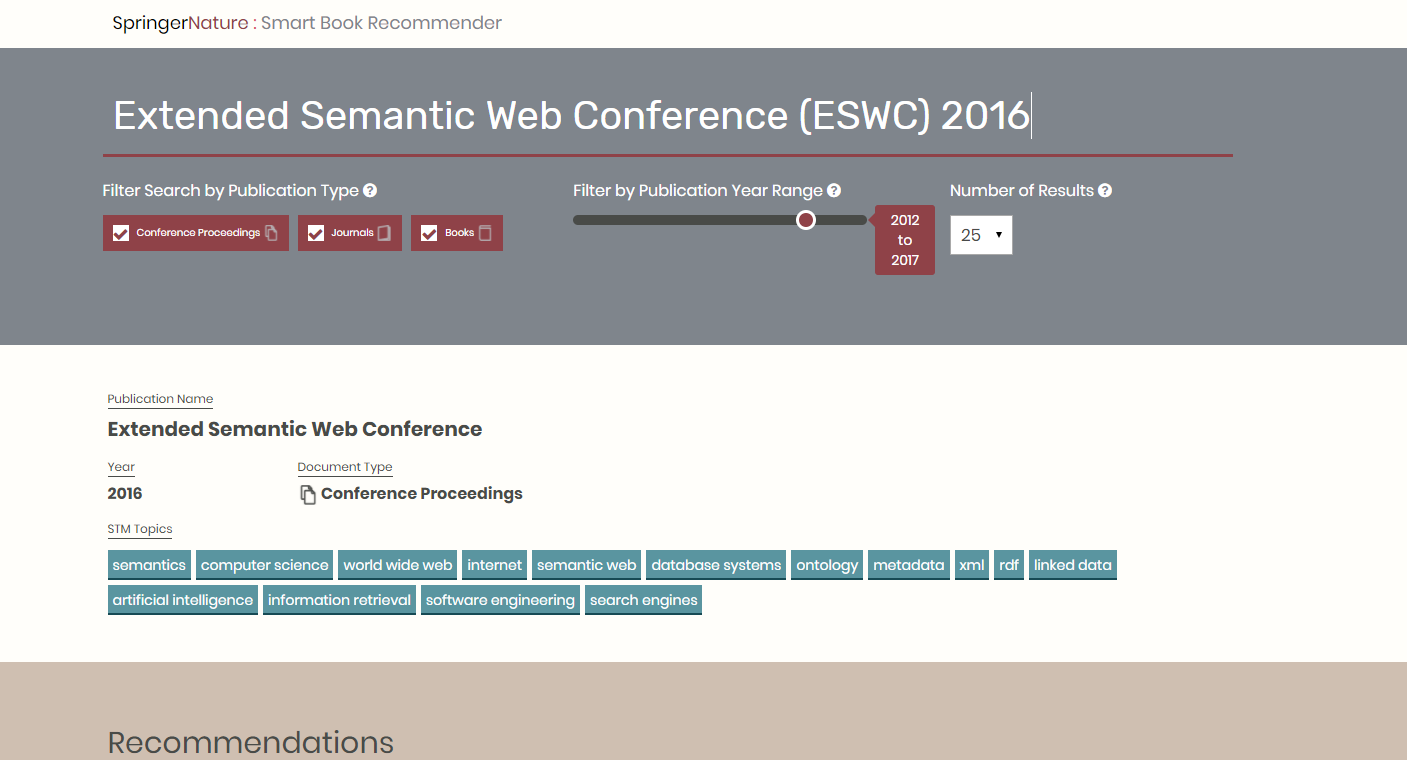
Smart Book Recommender
The Smart Book Recommender (SBR) is a semantic application designed to support the Springer Nature editorial team in promoting their publications at Computer Science venues. It takes as input the proceedings of a conference and suggests books, journals, and other conference proceedings that are likely to be relevant to the attendees of the conference in question. It […]
Supporting Springer Nature Editors by means of Semantic Technologies
“Supporting Springer Nature Editors by means of Semantic Technologies” is a research paper accepted to the Industry Track at the International Semantic Web Conference (ISWC) 2017 , 21-25 October 2017, Vienna, Austria. Authors Francesco Osborne, Angelo Salatino, Thiviyan Thanapalasingam, Aliaksandr Birukou and Enrico Motta Abstract The Open University and Springer Nature have been collaborating since 2015 […]