
Classifying research papers according to their research topics is an important task to improve their retrievability, assist the creation of smart analytics, and support a variety of approaches for analysing and making sense of the research environment. In this page, we present the CSO Classifier, a new unsupervised approach for automatically classifying research papers according to the Computer Science Ontology (CSO), a comprehensive ontology of research areas in the field of Computer Science.
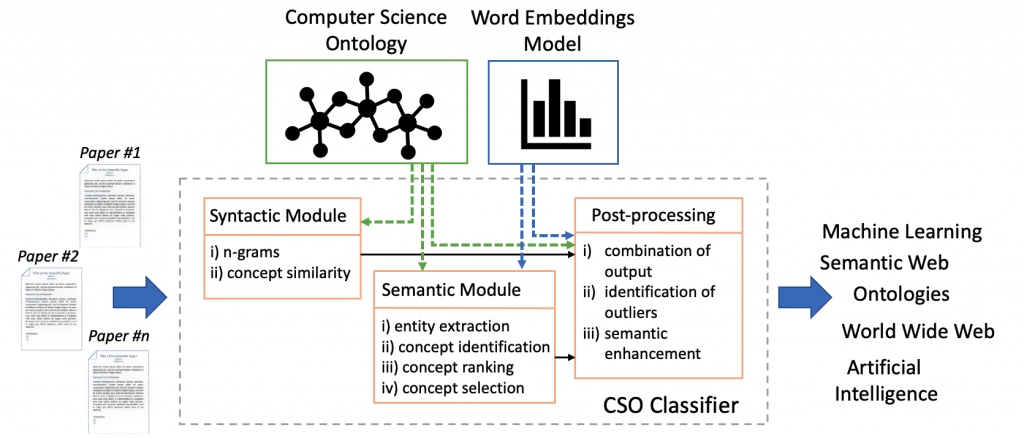
The CSO Classifier takes as input the metadata associated with a research paper (title, abstract, keywords) and returns a selection of research concepts drawn from the ontology. It consists of two main components: (i) the syntactic module and (ii) the semantic module. Figure 1 depicts its architecture. The syntactic module parses the input documents and identifies CSO concepts that are explicitly referred in the document. The semantic module uses part-of-speech tagging to identify promising terms and then exploits word embeddings to infer semantically related topics. Finally, the CSO Classifier combines the results of these two modules, identifies outlier, and enhances them by including relevant super-areas.
We developed the classifier in Python 3 and we release it under Apache 2.0 Licence.
Relevant papers
If you want to know more about this research initiative please refer to the following papers:
- Salatino, A.A., Osborne, F., Motta, E., CSO Classifier 3.0: A Scalable Unsupervised Method for Classifying Documents in Terms of Research Topics. In International Journal on Digital Libraries, Springer, 2021 Read from ORO
- Salatino, A.A., Osborne, F., Thanapalasingam, T., Motta, E.: The CSO Classifier: Ontology-Driven Detection of Research Topics in Scholarly Articles. In: TPDL 2019: 23rd International Conference on Theory and Practice of Digital Libraries. Springer. Read from ORO
- Salatino, A.A., Thanapalasingam, T., Mannocci, A., Osborne, F. and Motta, E. 2018. Classifying Research Papers with the Computer Science Ontology. ISWC-P&D-Industry-BlueSky 2018 (2018). Read from ORO
Download and install
The CSO Classifier is an ongoing project. You can follow its development through our Github repository https://github.com/angelosalatino/cso-classifier, or you can download the latest release from Zenodo:
![]()
You can also install the CSO Classifier using the package manager for Python:
![]()
- Ensure you have Python 3.6 or above installed. Download latest version.
- Use pip to install the classifier:
pip install cso-classifier - Download English package for spaCy using
python -m spacy download en_core_web_sm

